The unofficial guide to extracting google search results in 2021 with Elixir.

In one of my previous articles, we discussed why one might want to extract data from the Internet. Also, I have created a small article that demonstrates how to extract data for the real estate agency; Now, we would take a step in a slightly different direction — our new target is Google.
Imagine we’re a marketing agency trying to work for a company and promote it in google search results. In this situation, it’s important to trace the results of marketing activities to understand how different marketing activities influence clients' positions in search results.
Note: According to the robots.txt available on google.com the crawling of the search results is generally not desired. However, we also see that there are some exceptions for some bots (like tweeter, etc). Quick search on how to scrape google is showing dozens of similar tutorials but for other languages, so why not show the one for Elixir?
The task
In this example, we will build a crawler that will extract:
- Title
- Link
- Description
Getting started
As usual in these cases, we will start with a fresh Crawly project:
mix new google_serp --supAdd Crawly & Floki to the mix file:
defp deps() do
[
{:crawly, "~> 0.12.0"},
{:floki, "~> 0.26.0"}
]
endCreate the config folder and config.exs file
Getting around
As soon as everything is set up, we can glance at the target website to find extractors.
Let's fetch the search results page and see how to extract it:
An interesting part here is that the body is represented in the ISO-8859–1 encoding. That’s why we would have to convert it to UTF8 first so it will be easier to proceed with parsing, see also a discussion here. We will use Codepagex for that purpose.
Now it’s time to open the page with Google Inspect console (ideally with disabled JS) to start finding correct selectors.
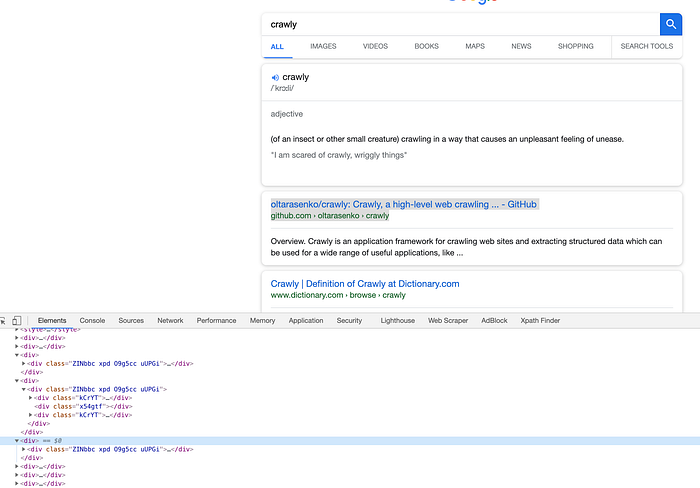
As you can see from the picture above, it’s possible to access all blocks by the `.ZINbbc` (it will also be required to remove the first element of that list that does not seem relevant to search results). We came with the following selectors:
Now finally, it’s time to convert this into a spider. Ideally, we would want to get a search query as a starting parameter for the spider, so let’s achieve it :).
We came with the following code:
You can clone the resulting project here.
Conclusion
In this article, we have shown how to extract data from google search results. It is a bit of an incomplete example, as we’re not following the pagination yet. If this article ever gets 200 claps, I will create a second article explaining how to follow all pages of google search results.
UPDATE
As soon as we have gathered the required 200 claps, I am preparing the second part of the article! Please stay connected!
