Web scraping with Elixir and Crawly. Extracting data behind authentication.

In our previous articles, we have covered the topic of web scraping with Elixir, and have shown how Crawly can simplify this work if you need to render dynamic content.
I will demonstrate how Crawly can extract data that is behind a login (this is not a trivial problem to solve without the right tools).
This might be required in several cases. For example when you want to extract profile data from another social network. Or for example, when you want to extract and analyze special offers that are only available to members of a specific website.
In this article, we will show how to set up a crawler that will extract data from http://quotes.toscrape.com/ (a special website built to experiment with web crawling), this site has some information that is only available if you can authenticate your requests.
Exploring the target
First of all, let’s look at the http://quotes.toscrape.com/ website, to analyze the target and to set the requirements. The website looks like this:

As you can see, http://quotes.toscrape.com/ is quite a simple website, it does however contain a login link, which brings you to a login form. As it is a training site, this login form will accept any login/password combination.
Of course, normal login forms will require real credentials.
Now let's see what the website looks like after we perform the authorization:

The task: So now, as soon as we have explored the target a bit, let's extract the following fields from the website: quotes, authors, tags, and goodreads_link.
Bootstrapping the project
Now as we have a task, bootstrap everything, complete the following steps from the Quickstart guide:
- Create a project
mix new quotes -- sup2. Add Crawly & Floki to the mix file:
defp deps() do
[
{:crawly, "~> 0.12.0"},
{:floki, "~> 0.26.0"}
]
end3. Create the config folder and config.exs file
use Mix.Config
config :crawly,
closespider_timeout: 10,
concurrent_requests_per_domain: 8,
middlewares: [
Crawly.Middlewares.DomainFilter,
Crawly.Middlewares.UniqueRequest,
Crawly.Middlewares.AutoCookiesManager,
{Crawly.Middlewares.UserAgent, user_agents: ["Crawly Bot"]}
],
pipelines: [
{Crawly.Pipelines.Validate, fields: [:quote, :author, :tags]},
Crawly.Pipelines.JSONEncoder,
{Crawly.Pipelines.WriteToFile, extension: "json", folder: "/tmp"}
]4. Define the spider file: quotes_spider.ex
defmodule QuotesSpider do
use Crawly.Spider
alias Crawly.Utils
@impl Crawly.Spider
def base_url(), do: "http://quotes.toscrape.com/"
@impl Crawly.Spider
def init(), do: [start_urls: ["http://quotes.toscrape.com/"]]
@impl Crawly.Spider
def parse_item(response) do
%{
:requests => [],
:items => []
}
end
endAt this point, we have finished bootstrapping the project, so it’s time to add real code in the parse_item function, to get real data extracted.
Extracting the data
At this point, we should explore the target website in order to find out selectors that would allow us to extract items and to find out how to crawl it. The process is also described in Crawly Tutorial, but we decided to follow the full process here, to make this tutorial self-containing, hopefully, you will forgive us for that redundancy. Let’s open the Elixir shell of our project:
iex -S mixAnd let’s fetch the page with the help of Crawly, so we can experiment with it, in order to find out appropriate selectors:
response = Crawly.fetch("http://quotes.toscrape.com/")
{:ok, document} = Floki.parse_document(response.body)Now as we have data in our console, let's start extracting the required parts one by one.
Links to follow
Open the website, with a Chrome Inspector, to find the links that the crawler will need to navigate in order to find all the relevant items:
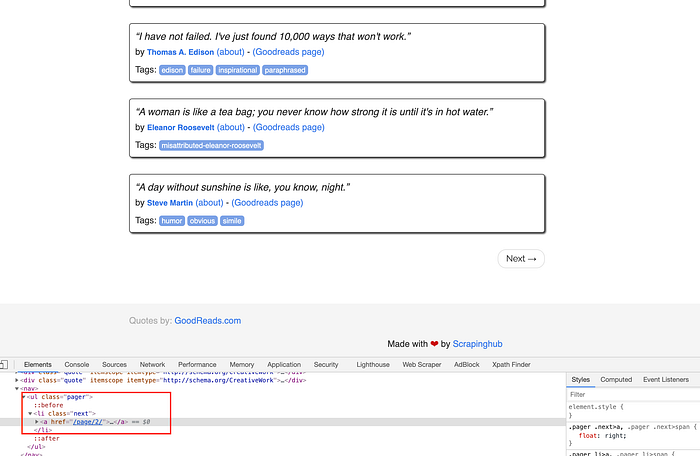
So as you can see, the page contains a Next link that has a dedicated CSS class (next). We can use this information to build a relevant Floki selector, in the console try the following lines:
(
links =
document
|> Floki.find("li.next a")
|> Floki.attribute("href")
)["/page/2/"]
As you can see, we have successfully converted the highlighted part of the page into the data with the help of Floki.
Getting the items
Now, let’s use Chrome Inspector in order to see how the items are represented on the same page:
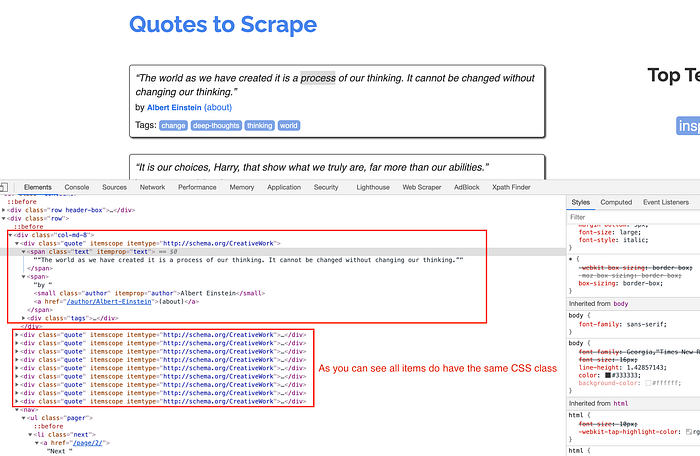
As you can see, all quotes are marked with the same CSS style quote. So as soon as we find extractors for all fields on one quote, we will just loop through every quote getting everything.
We came up with the following set of selectors which allow for that extraction of data from the individual quote:
item_block = Floki.find(document, ".quote") |> List.first()
quote = Floki.find(item_block, ".text") |> Floki.text()
author = Floki.find(item_block, ".author") |> Floki.text()
tags = Floki.find(item_block, ".tags a.tag") |> Enum.map(&Floki.text/1)(
goodreads_link = Floki.find(item_block, "a:fl-contains('(Goodreads page)')")
|> Floki.attribute("href")
|> Floki.text()
)
As you can see the goodreads_link can’t be extracted yet, as we have not authenticated our request yet.
Doing the login
A request needs to be authenticated, in order to get the goodreads_link . Technically it means that we need to obtain the session cookie and stuff it into a Crawly request, once done the Crawly.Middlewares.AutoCookiesManager middleware will take care of automatically adding it to every new request. But how do we get the session cookie?
It should be as simple as submitting a login form and getting cookies from the response.
Let's look at the login form:

As you can see from the screenshot above, the login form contains 3 inputs (csrf_token, username, and password). And I guess, nowadays, everyone already knows that the CSRF is the special method, which prevents scripted form submissions :(.
How to deal with a form which has a CSRF field?
Well, of course, there are ways to submit forms with CSRF token protection. Let’s explain how this verification works:
- A server generates a unique token + unique cookie (which matches the token of course) and sends them to a client.
- The token is injected into that beautiful “hidden” form field, and the cookie is just processed by the browser as normally (e.g. stored and assigned to your session).
- Finally, when you submit a form, the server would verify that a token and cookie you’re sending are matching each other.
This means that we can successfully submit a POST request if we extract the csrf_token and the cookie from the login page. Which was translated into the following code:
def get_session_cookie(username, password) do
action_url = "http://quotes.toscrape.com/login"
response = Crawly.fetch(action_url)
# Extract cookie from headers
{{"Set-Cookie", cookie}, _headers} = List.keytake(response.headers, "Set-Cookie", 0)
# Extract CSRF token from body
{:ok, document} = Floki.parse_document(response.body)
csrf =
document
|> Floki.find("form input[name='csrf_token']")
|> Floki.attribute("value")
|> Floki.text()
# Prepare and send the request. The given login form accepts any
# login/password pair
req_body =
%{
"username" => username,
"password" => password,
"csrf_token" => csrf
}
|> URI.encode_query()
{:ok, login_response} =
HTTPoison.post(action_url, req_body, %{
"Content-Type" => "application/x-www-form-urlencoded",
"Cookie" => cookie
})
{{"Set-Cookie", session_cookie}, _headers} =
List.keytake(login_response.headers, "Set-Cookie", 0)
session_cookie
endNow once this operation is done, we should modify our init() function, so it produces the first authenticated request.
def init() do
session_cookie = get_session_cookie("any_username", "any_password")
[
start_requests: [
Crawly.Request.new("http://quotes.toscrape.com/", [{"Cookie", session_cookie}])
]
]
endFinally the full spider code we came with looks like this:
defmodule QuotesSpider do
use Crawly.Spider
alias Crawly.Utils
@impl Crawly.Spider
def base_url(), do: "http://quotes.toscrape.com/"
@impl Crawly.Spider
def init() do
session_cookie = get_session_cookie("any_username", "any_password")
[
start_requests: [
Crawly.Request.new("http://quotes.toscrape.com/", [{"Cookie", session_cookie}])
]
]
end
@impl Crawly.Spider
def parse_item(response) do
{:ok, document} = Floki.parse_document(response.body)
# Extract request from pagination links
requests =
document
|> Floki.find("li.next a")
|> Floki.attribute("href")
|> Utils.build_absolute_urls(response.request_url)
|> Utils.requests_from_urls()
items =
document
|> Floki.find(".quote")
|> Enum.map(&parse_quote_block/1)
%{
:requests => requests,
:items => items
}
end
defp parse_quote_block(block) do
%{
quote: Floki.find(block, ".text") |> Floki.text(),
author: Floki.find(block, ".author") |> Floki.text(),
tags: Floki.find(block, ".tags a.tag") |> Enum.map(&Floki.text/1),
goodreads_link:
Floki.find(block, "a:fl-contains('(Goodreads page)')")
|> Floki.attribute("href")
|> Floki.text()
}
end
def get_session_cookie(username, password) do
action_url = "http://quotes.toscrape.com/login"
response = Crawly.fetch(action_url)
# Extract cookie from headers
{{"Set-Cookie", cookie}, _headers} = List.keytake(response.headers, "Set-Cookie", 0)
# Extract CSRF token from body
{:ok, document} = Floki.parse_document(response.body)
csrf =
document
|> Floki.find("form input[name='csrf_token']")
|> Floki.attribute("value")
|> Floki.text()
# Prepare and send the request. The given login form accepts any
# login/password pair
req_body =
%{
"username" => username,
"password" => password,
"csrf_token" => csrf
}
|> URI.encode_query()
{:ok, login_response} =
HTTPoison.post(action_url, req_body, %{
"Content-Type" => "application/x-www-form-urlencoded",
"Cookie" => cookie
})
{{"Set-Cookie", session_cookie}, _headers} =
List.keytake(login_response.headers, "Set-Cookie", 0)
session_cookie
end
endAlternatively, you can check out the full project here: https://github.com/oltarasenko/crawly-login-example
Conclusions
In this article, we have shown how to authenticate your request to extract data from the protected areas of a website. Please be advised that some websites will not want their private pages to be scraped, so please always check the terms & conditions of the individual websites before moving forward, as otherwise, you may face technical or legal issues.
Looking for more?
Sometimes web scraping might be complex. We consider scraping to be the process that involves development, quality assurance, monitoring, and other activities. That’s why we have built an open-source tool that allows you to develop, schedule, and verify your distributed Crawls. Sounds interesting? Check the Crawly UI.
